
- Using player statistics of fundamentals (e.g. rebounds per game) to predict outcomes of games.
- Trying to assign a probability of victory, rather than just a "X team wins" result.
- Reasoning about the structure of the tournament itself (i.e. a #1 seed has an easier path to the championship than a #14 seed).
Player statistics
Last year, I had a lot of discussion with people about whether my model could account for late-season roster changes (e.g. last year I think there was a late change to the BYU roster). In short, my EigenBracket model could not account for those effects. To remedy that, I tried to include an explicit representation of players in the model this year, by looking at their individual statistics, including per game field goals, three pointers, free throws, rebounds, total points, assists, turnovers, steals, blocks and fouls. To summarize these parameters for an entire team, I took the weighted average of individual statistics, weighting on the average playtime per game of each player. The idea was that, in the event of a late-season roster change, that I could remove that player from the weighted average to model the impact on the team.Armed with these summarized statistics, I set out to see if I could predict game outcomes using them (with Win-Loss data too, as I did last year).
Probability of Victory
Determining the probability of a victory of Team X over Team Y is most easily accomplished by training a statistical model. One convenient method of doing this is to build a Bayesian model. In short, these models are helpful when reasoning probabilistically about some hidden variable (will a team achieve victory) given a set of observations.
Every variable ("node") in the model has a finite set of states (e.g. True, False, etc.). Nodes are connected by directed interconnections, called edges. Edges between nodes essentially means "if the state of the (parent) variable is known, then I know something about the state of this other (child) variable."
For example, if you had your eyes closed while your favorite team was shooting a game-deciding free throw on the home court, you could still infer (probabilistically) whether the basket went in, based only on listening to whether the person next to you started cheering. (But, this wouldn't tell you with certainty; your seat-neighbor might be a fan of the other team. Nevertheless, it does update your belief in whether the basket was scored). Thus, the [True, False] states of the Cheering variable, update your belief about the BasketScored state [Yes, No] and we would draw an edge between these variables.
I divided observations into two categories: those based on Win-Loss history and those based on player statistics:
- For the Win-Loss history, I essentially calculated an ELO rating for each team. I considered using the Eigenvector Centrality score from last year, but - since it was highly correlated with ELO scores anyway - thought a single feature was sufficient.
- For Fundamentals, I used player statistics: per game field goals, three pointers, free throws, rebounds, total points, assists, turnovers, steals, blocks and fouls.
The full model is shown below, the available states of each node is shown in brackets:
 |
| Bayesian model used for calculating the probability of victory given two team's Win-Loss history and aggregate player statistics. |
The thickness of the edge is related to the "strength of influence". Thus, Win-Loss history (ELO scores) seem to be more predictive of victory than Fundamentals. Amongst fundamentals, offensive parameters (Field Goals per game, etc) and Rebounds seem to be more predictive than defensive parameters (blocks, steals) or fouls.
But those conclusions should be taken with a grain of salt: I think the Fundamentals predictor is pretty weak. Most of the predictive power of the model seems to come from Win-Loss data. If the ELO node is removed from the model, a lot of the predictive power is lost.
For model building, and for prediction, I used the fantastic GeNIe bayesian analysis software from the University of Pittsburgh's Decisions Systems Laboratory.
Structure of the Tournament
Actually, it turns out that using a Bayesian network is also a great way of modeling the tournament itself. If every game is seen as having a probabilistic outcome (i.e. "Team X would beat Team Y nine times out of ten, on a neutral field"), the probability of each team reaching a given round can be explicitly modeled. The Bayesian network actually has the same familiar form of a tournament bracket:
 |
| Subset of the full tournament Bayesian network (shown: upper part of the Midwest region bracket) |
Each node in the tournament has a set of states that describe each of the possible teams that can reach that node. For example, the uppermost Sweet 16 bracket in the Midwest region is reachable by four teams: Louisville, N.C. A&T, Colorado State and Missouri. Thus, the node in the network representing the team reading the Sweet 16 from that part of the bracket has four states (each team). Using Bayesian algorithms, we can calculate a vector of numbers describing how likely each of those states are (and, therefore, how likely each team is to reach the Sweet 16). That vector doesn't have to be specified by the user; instead, it is calculated and depends on the vectors of the games immediately preceding it. In this year's tournament, that means that the Upper-Midwest Sweet 16 node depends on the outcome of the Louisville vs N.C. A&T game, as well as the Colorado State vs Missouri game. Thus, we can specify a conditional probability matrix for that Sweet 16 node, as follows:
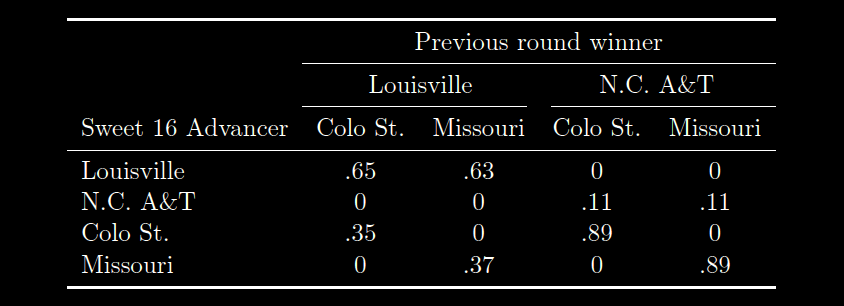
Here, the entries in the rows tell us how likely it is for a given team to advance, given the outcomes of the two games. So, the .65 in the first line tell us that if Louisville and Colorado St. are victorious in the first round (and thus end up playing one another for the Sweet 16 slot), the probability that Louisville advances is 65%. Contrastingly, the .35 in the third row tells us the probability of Colo. St. advancing (given Colorado St plays Louisville) is only 35%. These percentages come from the "Probability of Victory" Bayesian model, that I explained in the last section. Note that the probability of N.C. A&T or Missouri advancing to the Sweet 16 is zero in the first column. This is because, if Louisville and Colorado State are playing for the Sweet 16 slot, then both N.C. A&T and Missouri have already been eliminated, and therefore, (obviously) cannot advance. The other columns consider the other possibilities for the results of the previous games (e.g. column two considers that Louisville and Missouri won in the previous round).
Similar, but more complicated, conditional probability matrices are defined for all the other states in the tournament. For example, each Final Four node has a matrix with 16 rows and 8x8=64 columns, because there are 16 possible teams that could occupy any given Final Four spot and there are 8 possible teams that could occupy each of the immediately proceeding Elite Eight spots.
Thus, a Bayesian model of the tournament in this manner allows us to efficiently consider all possible "what-if" scenarios of the tournament!
I built the Bayesian model of the tournament, and all of the conditional probabilities matrices, programatically, as I was not keen to specify the 64x32x32 = 65,536 entries required for the Championship node by hand! For that I used the SMILE library, which is the programming library counterpart to the aforementioned GeNIe program.
Predictions and Selecting the Bracket
The above two models enabled explicit calculation of the probability that each team reaches each round of the tournament. Shown below is a summary of these probabilities for the 10 teams my method predicts to be most likely to win the overall championship:
I thought predicting the tournament would be straightforward using this information, but there seems to be some subtlety here. Suppose you start assigning the results in the 2nd round, then proceed to the Sweet 16 when that is finished, then to the Elite Eight, etc., choosing the team most likely to reach each of those nodes in turn. Will that produce the optimal bracket? I thought so!
However, consider this scenario: you have four teams. Two of them are excellent, called QuiteGood and AlsoGood. If they play each other, it's usually a pretty even game, but QuiteGood wins 51% of the time. There are two other teams: Decent and Terrible. Terrible essentially always loses (99% of the time). If Decent plays either of QuiteGood or AlsoGood, Decent wins only 40% of the time, and loses 60% of the time. So consider this bracket seeding:


No! QuiteGood only plays in the championship 51% of the time and of that 51%, they only win 60% of the time. Thus, their total probability of winning the championship is .51*.60 = .306 = 30.6%. By contrast, Decent almost always gets to play in the championship game, and wins 40% of the time. So Decent's probability of winning the tournament is 39.6%! So Decent is the most likely winner of the tournament.
Since most scoring systems give greater weight to later games, predicting the champion with as much accuracy as possible is important.
Thus, in this simple scenario, the optimal bracket is not equivalent to the most likely bracket. The optimal bracket is:

Obviously, the tournament seeding system is designed to avoid this scenario (i.e. good teams playing each other early), but that's no reason to rely on the tournament designers! Indeed, if they were so good at correctly choosing seeds, perhaps we needn't even run a tournament at all! Clearly, we should keep our own counsel about which teams are good.
Anyway, the practical result from this thought experiment is that calculating the bracket should proceed backwards. Choose the tournament champion first, then the teams who reach the championship game, then the teams who reach the Final Four, etc. In each case, I calculated my bracket by choosing the team with maximum probability to reach the furthest current round, working backward, but skipping teams when there was some bracketological impossibility. For example, both Louisville (#1 in Midwest) and Duke (#2 in Midwest) cannot both reach the Final Four due to the structure of the tournament. Thus Duke would have to be selected in an earlier round in the tournament (e.g. the Elite Eight), but that would be dealt with after assigning the Final Four round selections.
Downloads
Using this procedure, I obtained a final bracket, available by clicking here!
Additionally, you can feel free to look at my predictions for tournament survival probabilities, by clicking here!